I partly
talked about this before but theres been a series of updates which I couldn't help but blog about.
So I was talking to Miles about a client which could support much more that Microblogging and we were suprised that no ones actually built a clever client app which supports Microblogging + RSS + XMPP? Well the closes we can find to that idea is a OSX application called Eventbox. Actually this blog entry does a much better job explaining what it can do, and what a difference it means for advanced users.

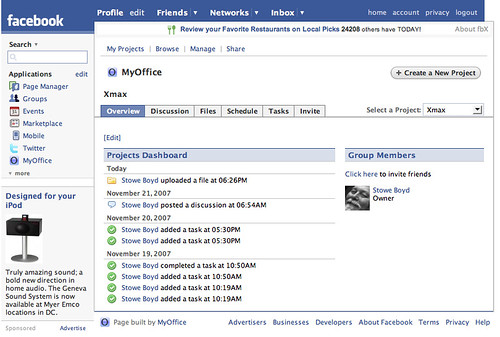
If you imagine the dashboard of Facebook (credit to Stowe Boyd) but under your control using the services you prefer. Fan of Flickr, just add them and the RSS feed. Prefer photobucket use that instead. Its a bit like the life streaming services such as Plaxo, Mybloglog and Friendfeed. The application/client should be clever enough to look at the service and work out through maybe some discovery service/xml whats possible with the service. So for example adding Twitter will allow you to post and read, while a flickr feed won't. It would be cool to also finally start adding some of those comment services into the mix, so for example allow backtype comments if you start adding stuff to a RSS feed from a blog. Hell why not add a proper metaweblog/atom Blog editor too maybe?
Anyway, Eventbox is close and seems to be on the right track and I was starting to get worried that once again the linux platform would be left behind in this area. But I was wrong actually deadly wrong because under my own nose was Gwibber.
I've been using it for a while now and its actually fended off competition from Air apps like Twitterdeck (far too twitterfied) and Twirl (crashes a lot) for my ubuntu desktop. But what shocked me today when talking to Miles was the new supported protocals it has. I had done updates and never knew about the new features.

So now theres support for,
- RSS/Atom
- Digg
- La.conica
- Twitter
- Pidgin
- Ping.fm
- Facebook
- Jaiku
- Pownce
- Flickr
- Indenti.ca
So most of the Microblogging services including the recently defunked Pownce and open source La.conica. RSS including automatic discovery for Digg and Flickr. Then some of the interesting ones, Facebook with the ability to also send messages into the Facebook paywall. Ping.FM support, means you can send from Gwibber to all those other services such as Brightkite, Rejaw, etc, etc. But the one which is strange and most exciting is Pidgin support. The problem is, there is no documentation for the Pidgin part and the account says you can send only. So after some playing around, I worked out that when you send a message on Gwibber, it will also set the status of Pidgin. This is cool, but I also want the ability to recieve XMPP messages straight into Gwibber.

Actually Gwibber has the structure to really move forward. I've already seen multiple types of authentication from username/password to a Oauth like facebook auth. Each protocal gets its own colour which you can set and you can enable recieve, send and search on each one (protocal supporting). Search works well, but I'll like to see some kind of watch or a pounce system like you get in Pidgin or Specto. Finally it would be useful to support the Newsgator API (yep I switched from bloglines to newsgator) for RSS, so you can properly manage the RSS and not end up reading the same news over and over again.
Technorati Tags: gwibber, microblogging, linux, client, stream, flow, eventbox, xmpp, twitter
Comments [Comments]
Trackbacks [0]









{kind=link}